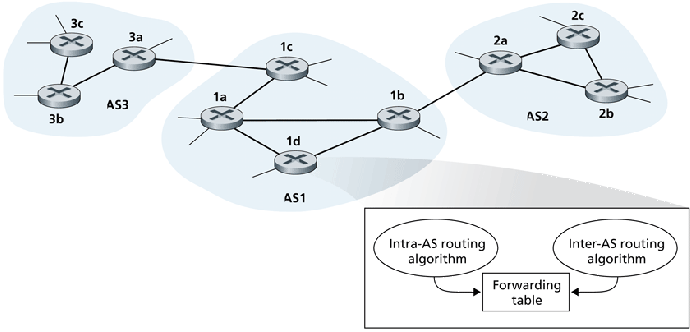
Hence, we only need consider routing between routers.
- A set of vertices/nodes representing the routers.
- A set of labeled edges, representing the links between routers.
The edge labels specify the cost of the link.
- Several ways to assign link costs:
- Assign a cost of 1 to every link.
Minimizes hop count.
- Assign cost as the inverse of link speed.
Maximizing use of high speed links.
- Assign costs for political/business reasons.
Discourage use of certain links.
- Assign a cost of 1 to every link.
- A path/route is an ordered list of connected vertices, from source
to destination:
- Path cost is the sum of the edge costs along the path.
- Routing algorithms work to minimize all path costs.
- Path cost is the sum of the edge costs along the path.
Example network represented as a graph:
![\includegraphics[width=3.5in]{Figures/fig04_27.eps}](apr25img1.png)
- Global: the routing algorithm knows the connectivity status and
cost of all links in the network.
The algorithm might be run at one centralized location or multiple sites.
Referred to as link state algorithms.
How is link state information acquired? How much overhead in acquiring this information?
- Decentralized: the routing algorithm runs in an iterative,
distributed manner within each router.
Routers only know the cost of their directly-connected links, and share routing information with their neighbors.
After a number of iterations, routers converge on the least-cost routes.
Referred to as distance vector algorithms, as routers maintain a vector of distances (costs) to other routers.
![\includegraphics[width=5in]{Figures/fig04_28.eps}](apr25img4.png)
![\includegraphics[width=3in]{Figures/fig04_29a.eps}](apr25img6.png)
![\includegraphics[width=3in]{Figures/fig04_29b.eps}](apr25img7.png)
![\includegraphics[width=3in]{Figures/fig04_29c.eps}](apr25img8.png)
![\includegraphics[width=3in]{Figures/fig04_29d.eps}](apr25img9.png)
![\includegraphics[width=5in]{Figures/fig04_30.eps}](apr25img10.png)
![\includegraphics[width=5in]{Figures/fig04_31.eps}](apr25img11.png)