Transport Layer Congestion Control
Tom Kelliher, CS 325
Apr. 7, 2008
Read 4.1-4.3.
TCP Reliability.
- Congestion control principles.
- TCP congestion control.
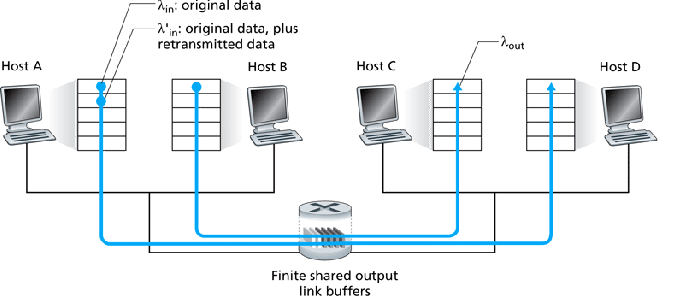
Network layer introduction.
- Assume no segments are dropped and senders don't time-out any
segments -- no retransmits.
- The network load generated by each sender's application layer is
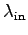 bps.
bps.
Assume the senders equally share the available bandwidth.
- The router's outgoing link has capacity R bps.
- The network load seen by the receiver's application layer is
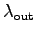 bps.
bps.
-
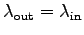 until we hit the bandwidth limit --
until we hit the bandwidth limit --
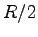 shared --
can't exceed this.
shared --
can't exceed this.
- As
approaches , the router's segment queue's
length -- and delay -- increases.
- Now, segments will be be dropped and retransmits will occur.
-
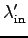 is the offered load of the transport layer.
is the offered load of the transport layer.
Due to retransmits,
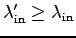 .
.
- Due to finite buffers,
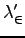 can't exceed -- shared
link capacity.
can't exceed -- shared
link capacity.
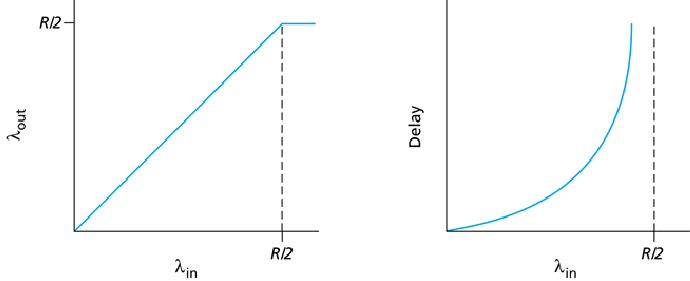
The graph on the left assumes the sender is omniscient and knows when the
router has free buffers and only transmits segments then, avoiding dropped
segments. -- unrealistic.
- Dropped segments mean duplicate, redundant data sent across a link
-- wasting bandwidth.
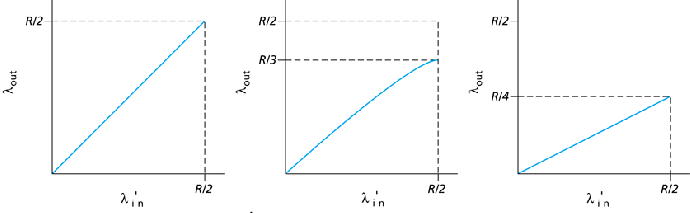
The middle graph shows what could happen if the sender retransmits only segments known to be lost -- again, unrealistic. Here, we assume
17% of segments are retransmits.
- Realistically, delays will cause some non-dropped segments to be
retransmitted, further wasting bandwidth with redundant segments.
The graph on the right shows this realistic scenario, assuming each segment
is retransmitted once.
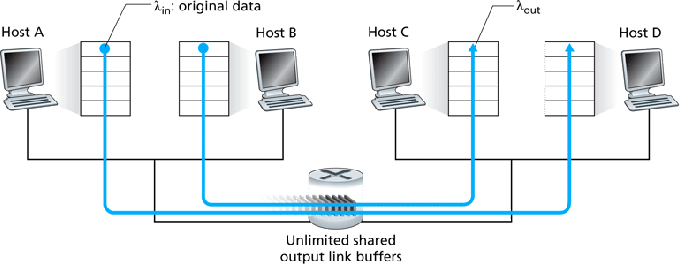
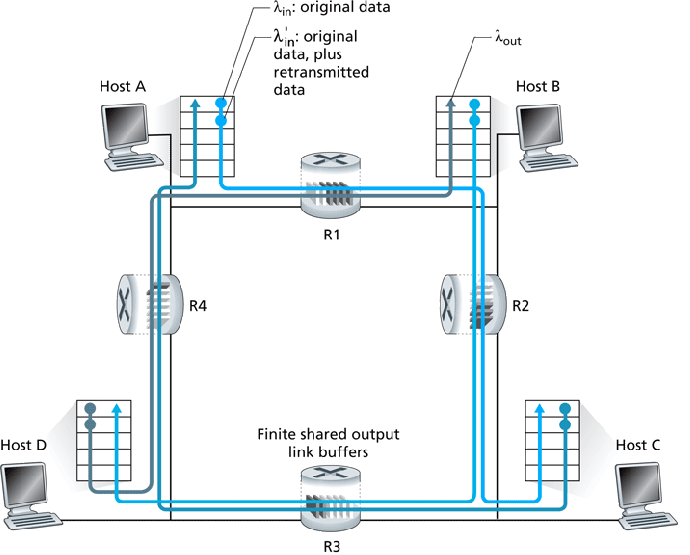
- Consider what could happen if R2 becomes congested due to B-D
traffic:
- R2 begins dropping segments from A-C, wasting bandwidth at R1.
- A's offered load increases, to handle retransmits.
- R1 could become congested, affecting the (initially free) D-B
route.
Worst case, B-D traffic could completely lock-out A-C traffic beyond the
point at which
saturates the routers' transmit
capacity:
Two approaches:
- End-to-end control:
- No help from network layer --sender/receiver have to intuit
congestion on their own.
- TCP intuits congestion through fast retransmits (triple ACKs),
not too bad -- some bandwidth still available; timeout transmits,
really bad -- no bandwidth available.
Third idea for TCP: increased RTTs mean congestion is beginning to
become a problem.
- Network assisted. Two approaches here:
- Direct feedback with choke packet -- router sends choke command
directly to sender.
- Indirect feedback with congestion indication bit in segment --
router sets this, when congested, as it forwards a segment to
receiver.
Receiver responsible for getting the indication back to the sender.
- Recall receive window for flow control:
- Recall our transmit model: sender sends
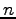 segments each RTT with
segments each RTT with
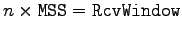 .
.
We therefore have
 .
.
So, RcvWindow, controlled by receiver, can be used to throttle sender
rate.
- TCP itself defines CongWindow, maintained by sender, to
throttle sender rate in face of congestion.
We then have:
Sender rate controlled by both RcvWindow and CongWindow.
TCP congestion control algorithm:
- Multiplicative decrease:
- After triple duplicate ACK, cut CongWindow in half. CongWindow never drops below 1 MSS.
Not as bad as a timeout.
- After a timeout, cut CongWindow down to 1 MSS.
- Additive increase:
- Increase CongWindow by 1 MSS each RTT.
Increase rate is controlled by RTT -- a lower RTT results in faster
CongWindow increase rate.
Often implemented by increasing CongWindow by
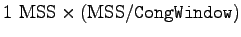 for each new ACK.
for each new ACK.
- Actually, CongWindow increase is multiplicative until Threshold is reached.
- Additive increase; multiplicative decrease:
- Slow start:
- CongWindow is set to 1 MSS for a new connection.
- CongWindow is increased by 1 MSS for each ACK received,
until Threshold is reached.
Exponential increase in CongWindow during SS phase:
- Additive increase, once Threshold reached:
TCP Reno = current algorithm. Is decrease from timeout or fast
retransmit?
- Actual timeout events behavior:
| State |
Event |
Sender Action |
Comment |
|
Slow Start (SS) |
New ACK received |
CongWin = CongWin + MSS. if
(CongWin  Threshold) set state to CA. Threshold) set state to CA. |
CongWin doubles every
RTT. |
|
Congestion Avoidance (CA) |
New ACK received |
CongWin = CongWin +
MSS(MSS/CongWin) |
CongWin increases by 1 MSS every RTT. |
|
SS or CA |
Triple Dup ACK |
Threshold = CongWin/2. CongWin = Threshold.
set state to CA. |
Fast recover; multiplicative decrease. |
|
SS or CA |
Timeout |
Threshold = CongWin/2. CongWin = 1 MSS. Set state to
SS. |
|
|
SS or CA |
Duplicate ACK received |
Increment duplicate ACK count for
segment |
|
Is TCP's AIMD algorithm fair? Consider this situation:
Suppose, initially, connection 1 has a higher throughput (CongWindow)
than connection 2:
This shows what happens during 3DupACK events -- multiplicative decrease.
Eventually, we converge to equal throughput.
On timeout, both connections will end up with a CongWindow of
1 MSS.
Thomas P. Kelliher
2008-04-03
Tom Kelliher
![\includegraphics[width=3.5in]{Figures/fig03_48.eps}](apr07img13.png)
![\includegraphics[width=4in]{Figures/fig03_49.eps}](apr07img14.png)
![\includegraphics[width=5in]{Figures/fig03_51.eps}](apr07img21.png)
![\includegraphics[width=4in]{Figures/fig03_52.eps}](apr07img22.png)
![\includegraphics[width=4in]{Figures/fig03_53.eps}](apr07img23.png)
![\includegraphics[width=4in]{Figures/fig03_54.eps}](apr07img25.png)
![\includegraphics[width=4in]{Figures/fig03_55.eps}](apr07img26.png)