Overview of Pipelining
Tom Kelliher, CS 240
Jan. 24, 2000
Review of single- and multiple-cycle implementations
- Overview of pipelining.
Pipelining.
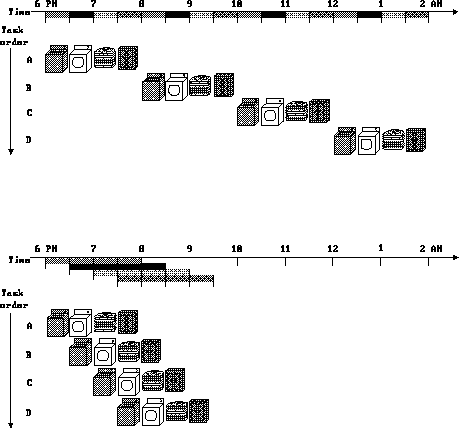
Experimental observations:
- If we hadn't pipelined, would it have taken longer?
- Did pipelining decrease the time it took an individual to move
through the line?
How did the speedup occur?
- Suppose at the end of the line we had two choices (say, ice cream and
pie), you could choose only one at the beginning of the line, and we had
the risk of running out.
What could happen?
The laundry analogy:
The five stage MIPS pipeline --- designed to promote pipelining:
- Instruction fetch.
All instructions same length.
- Decode and read registers.
The consistent placement of the source registers permits this.
- Execute ALU operation or calculate an address.
- Access memory.
Use of L1 caches to reduce contention.
- Result write-back.
Multiple reads/write.
Assume:
- Memory access is 2 ns.
- ALU use is 2 ns.
- Register file access is 1 ns.
Instruction class times:

Clock periods for the two implementations?
Execution example:
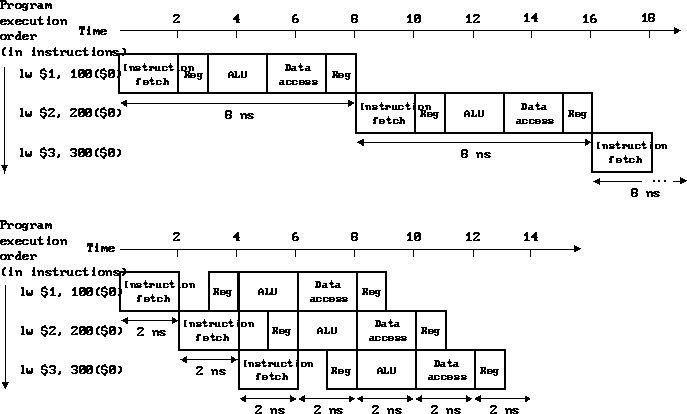
Note that pipelined register file reads are done during the second half of
the clock cycle and writes are done during the first half. Why?
Consider the speedup:
- Assumption: Stages are of equal length. What if they aren't?
- Speedup is at most the number of pipeline stages.
Do we achieve that?
Consider the execution of 1,000 instructions and compute the actual
speedup.
What happened? The cost of the pipeline registers.
Consider:
- How does the speedup occur?
- Shortened instruction execution time?
- Higher instruction bandwidth?
- Conditional branches.
Thomas P. Kelliher
Mon Jan 24 08:12:22 EST 2000
Tom Kelliher