Tom Kelliher, CS 240
Feb. 21, 2000
Assignment 1 due Wednesday.
The free list and reservation station. Intro. to simple superscalar pipeline.
Out of order execution (text, P Pro).
Continuing from last time:
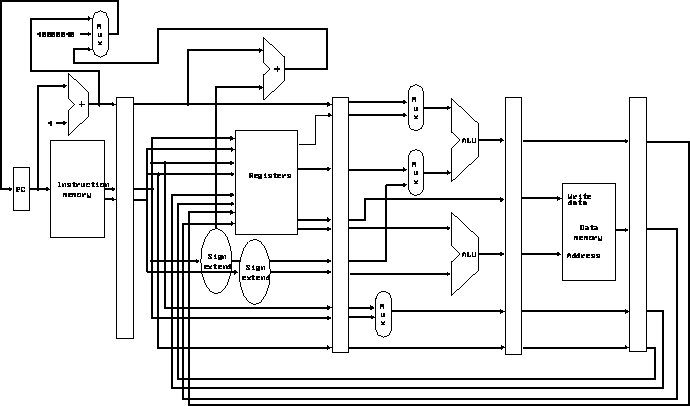
The pipeline:
What are the inter- and intra-instruction pair dependencies?
What are our options in increasing the functionality of that second ALU? (reg = reg op immed instrs, reg = reg op reg instrs) Additional dependencies?
Consider the code segment:
sum = 0; for (i = 0; i < last; ++i) sum += array[i];Which might compile to:
top: lw $t0, 0($s1)
addu $s2, $s2, $t0
addi $s1, $s1, -4
bne $s1, $0, top
How will the code be scheduled?
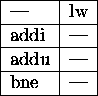
The addi could be raised, but what's it gain?
Suppose we unroll once:
top: lw $t0, 0($s1)
addu $s2, $s2, $t0
lw $t0, -4($s1)
addu $s2, $s2, $t0
addi $s1, $s1, -8
bne $s1, $0, top
Where are the stalls? How can we introduce temp variables to eliminate
some stalls?
How will the improved code schedule?
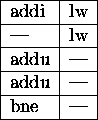
Is this an improvement?
By the way, what happens with the lw offsets?
Unroll twice more:

Is this an improvement?
When do you stop?
Suppose you don't have hardware integer multiply. Then you'll need something like:
a = mutiplicand; /* $s1 */
b = multiplier; /* $s2 */
product = 0; /* $s3 */
bit = 1; /* $s4 */
for (i = 0; i < 32; ++i) /* $s5 */
{
if (b & bit)
prod += a;
bit += bit;
a += a;
}
Which might compile to:
top: and $t0, $s2, $s4
beq $t0, $0, skip
addu $s3, $s3, $s1 /* addu1 */
skip: addu $s1, $s1, $s1 /* addu2 */
addu $s4, $s4, $s4 /* addu3 */
addi $s5, $s5, -1
bne $s5, $0, top
We can't get any speedup here.
Suppose we assume we can perform two R-format instructions simultaneously:

Assumptions:
Let's unroll once:
