Sensitive Data and Database Inference
Tom Kelliher, CS 325
Nov. 11, 2011
Written assignment due Friday, 11/18.
Read 7.1.
Database security and reliability.
- Sensitive data.
- Sensitive data inference.
- Availability and recovery issues.
Introduction to networks.
- Sensitive data: Data within a database that should not be public.
- What makes data sensitive?
- Inherently sensitive: An individual's salary.
- From a sensitive source: An informer whose identity must be kept
secret.
- Declared sensitive: An anonymous donor; Tom's ice cream
consumption.
- A sensitive attribute or sensitive record.
Some data within a table might be sensitive -- the salary field of a
personnel database or the ``Top Secret Flavor'' row in Moxley's ice
cream database.
- Sensitive in relation to previously disclosed data -- a partial
recipe for Coca Cola.
- Dilemma: Provide as much access as possible without compromising
sensitive data.
Another dilemma: security vs. precision.
- Factors entering into access decisions:
- Use -- rows may be locked during a transactions, preventing
access by other users.
- Acceptability -- a user may attempt to access sensitive data.
What about access non-sensitive fields of rows in which other fields are
sensitive? Generating a non-sensitive statistic from sensitive data?
- Role -- a user may only be permitted access during working
hours. The system may track previous queries, to ensure that a
combination of queries doesn't reveal sensitive data.
(This doesn't address possible conspiracies.)
- Types of disclosures:
- Exact data. Tom earned $20.13 last year.
- Bounds. Example: Professors earn between $100 and $1,000,000.
- Negative result. Person X does not have 0 felony
convictions.
- Existence. The fact that a certain piece of data even exists can
be sensitive. Example: The Math Department has an ice cream budget.
- Probable value. Using a series of queries to establish a likely
value for a sensitive piece of data.
Deriving sensitive data from non-sensitive data.
- Direct attack: Going directly for a sensitive data item.
Querying a database for salary data.
Possible to obscure a query using bogus conditions:
SELECT salary
FROM payroll
WHERE (lname = 'Smith') OR (sex <> 'M' AND sex <> 'F');
- Indirect attack: Derive sensitive data from non-sensitive statistics.
-- Assume there is only one record in payroll that has 'Segedy' in the
-- lname field.
SELECT sum(salary)
FROM payroll
WHERE lname <> 'Segedy';
SELECT sum(salary)
FROM payroll;
If this is still too overt, one can build a linear system of equations to
produce the result using as many queries as necessary to fool the system.
- Controlling the release of sensitive data.
- Limited response suppression.
``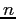 -item
-item 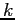 -response rule:'' If a query returns result rows and
these rows represent percent or more of the entire result, suppress
those items from the entire result.
-response rule:'' If a query returns result rows and
these rows represent percent or more of the entire result, suppress
those items from the entire result.
This may not be enough.
- Combined results: report various statistics.
As we have seen, it can be possible to circumvent this.
- Random sample. Construct a random sample of the database and run
the query on this subset.
Reduces precision.
- Random data perturbation. ``Tweak'' the results.
Maintenance of statistical properties?
- Query analysis. Track the user's query history, using it to
determine if sensitive data can be derived from the entire query set.
Multiple difficulties.
- Treat the database as if it were a class object and precisely
define the queries that can run via your business logic.
- A DBA's worst nightmare is a database crash or anything else that
results in a corrupted database.
- Some recovery techniques:
- Checkpoint the database at regular intervals and maintain update
logs.
Take the database back to the last checkpoint and replay the updates.
- Take regular backups.
Restore from a backup.
- Backup issues. Many databases need
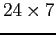 availability.
availability.
- Traditional backup software works at the filesystem level.
Database must be quiescent for this to work.
- Run the database's backup tool and then archive the script file it
generates.
This typically guarantees a consistent view of the database.
- If the database is on a RAID 1 device (mirrored), idle the
database momentarily, break the mirror, perform a traditional backup
from the backup disk, and, finally, re-establish the mirror.
Thomas P. Kelliher
2011-11-10
Tom Kelliher