The major conceptual breakthrough with threads is a usable shared address space. From this, the two most important advantages are:
- The consequence of a shared address space is shared data. This is what enables threads to cooperate among themselves. A user, without turning to the kernel for assistance (and avoiding the overhead) can implement a server capable of handling multiple requests simultaneously. Without this shared data, we couldn't have the situation of a task not blocking even though one of its threads has made a system call.
- Because of the shared address space, context switches between threads within the same task are performed quickly and efficiently. Overhead can be greatly reduced when compared to a heavy-weight process implementation.
Data sharing is a double-edged sword. I consider it also to be a major disadvantage of threads. I've seen what happens when user level threads walk over each others stacks; these interactions can introduce extremely subtle bugs which are mind-numbingly difficult to track down. Processes are insulated from each other and any interaction can be minimized and controlled.
``Fair'' thread management is also a problem. User level threads can suffer starvation problems. Kernel level threads begin to approach the complexity of processes.
- int fread(int sector, char *buff) --- Read data sector sector from the disk into buff. Block until the operation completes, returning 1 on success and 0 on failure.
- int fwrite(int sector, char *data) --- Write data from data to disk sector sector, blocking until the operation completes. Return 1 on success and 0 on failure.
Write pseudo-code for the disk process and the two system level library functions. Clearly indicate the content of mailbox messages.
Here's an example with three user processes:
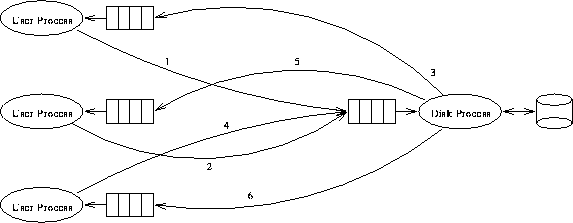
We can make several observations. The disk process is a ``well-known'' process, so all fread()s and fwrite()s will know what mailbox to use. On the other hand, the disk process must know what user mailbox is to be used for the reply, so the user's mailbox number must be part of the request. The request mailbox can certainly have a mixed set of read requests and write requests within.
A disk operation request message will contain these fields:
- Reply mailbox
- Read/Write indication
- Disk sector number
- Memory buffer/data block address
Send() does not block, therefore another mechanism must be used to block fread() and fwrite. The best choice is to perform a Receive, awaiting the status reply from the disk process.
The disk process communicates directly with the disk. It will perform all StartRead()s and StartWrite()s and busy wait on a disk.busy flag. Its request mailbox number is kept in the global variable DiskProcMbox, which is available to all processes.
Here are the functions:
int fread(int sector, char *buff) {
buffer reply;
// Assume every user process has a variable, MyMbox, which
// is the mailbox number for the process' replies
Send(DiskProcMbox, "<MyMbox>,<Read>,<sector>,<buff>");
Receive(MyMbox, &reply);
return reply == "OK";
}
int fwrite(int sector, char *data) {
buffer reply;
Send(DiskProcMbox, "<MyMbox>,<Write>,<sector>,<data>");
Receive(MyMbox, &reply);
return reply == "OK";
}
Here's the pseudo-code for the disk process:
DiskProcess() {
buffer request;
while (1) {
Receive(DiskProcMbox, &request); // get next request
// process next request
if (request.type == "Write")
StartWrite(disk, request.sector, request.data);
else if (request.type == "Read")
StartRead(disk, request.sector, request.buff);
else {
InvalidRequest(); // terminate offending process
continue; // skip busy wait and Send()
}
while (disk.busy) // wait for I/O to complete
;
Send(request.mbox, "<disk.status>") // disk.status is either "OK"
// or "ERROR"
}
}
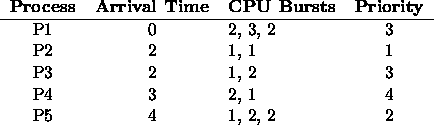
Draw four Gantt charts illustrating the execution of these processes using
FCFS (non-
preemptive), preemptive SJF, non-preemptive priority (a smaller
priority number implies a higher priority), and RR (quantum = 1).
Also, for each scheduling algorithm, answer the following:
- What is the turnaround time of each process?
- What is the waiting time of each process?
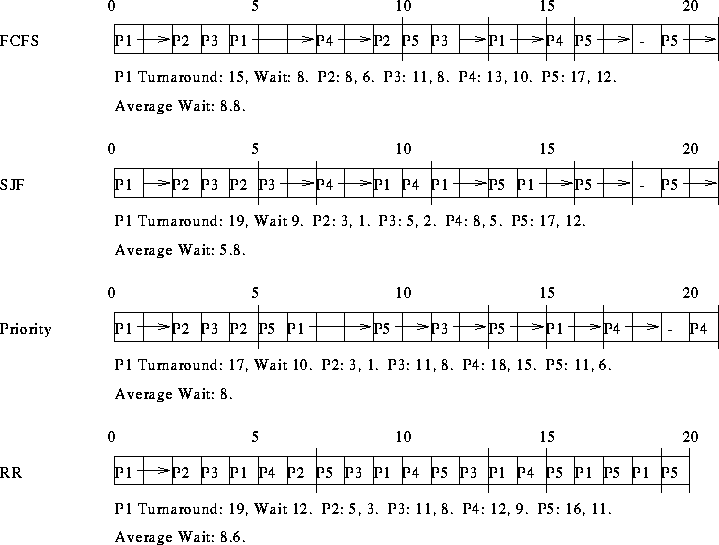
SRT results in the smallest average waiting time.
int flag[2] = { FALSE, FALSE } /* flag[i] indicates that Pi wants to */
/* enter its critical section */
int turn = 0; /* turn indicates which process has */
/* priority in entering its critical */
/* section */
flag[i] = TRUE;
while (flag[1 - i])
if (turn == 1 - i) {
flag[i] = FALSE;
while (turn == 1 - i)
;
flag[i] = TRUE;
}
CSi;
turn = 1 - i;
flag[i] = FALSE;
Prove that the algorithm satisfies the three requirements for a solution to
the CS problem.
- Mutual Exclusion --- Assume both processes are executing in their
critical sections. Note that each process has set its flag before entering
its critical section and leaves it set until after it leaves. Therefore,
both flags are set. Note also that a process only enters its critical
section if the other processes flag is reset. Therefore, both flags are
reset, a contradiction.
- Progress --- The flag of a process not in its critical section is
reset, allowing a process attempting to enter its critical section to
enter. If both processes attempt to enter critical sections at
approximately the same time, the turn checking code will cause one of
the processes to reset its flag, permitting the other process to enter its
critical section.
- Bounded Waiting --- If one process (B) is waiting at the spin loop
while the other (A) is executing its critical section, B will eventually
enter its critical section. This is due to the toggling of turn in
the critical section exit code. It will not necessarily enter its
critical section before A again enters its critical section. Until B sets
its flag true, A may enter its critical section many times, depending upon
the whims of the CPU scheduler. Once B sets its flag true, it will be the
next process to enter its critical section.