Tom Kelliher, CS 240
Apr. 16, 1999
New written assignment Monday.
Read 6.2.
Midterm, finished multicycle implementation.
Pipelining.
Bittersweet observations:
How did the speedup occur?
What could happen?
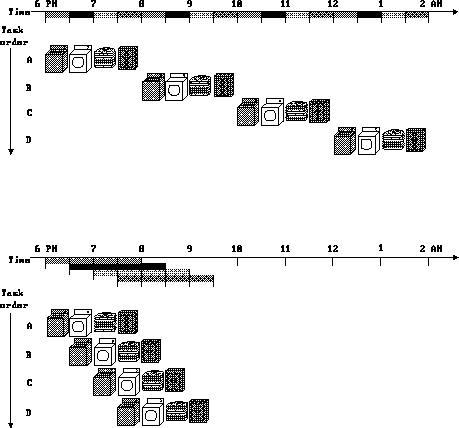
The laundry analogy:
The five stage MIPS pipeline --- designed to promote pipelining:
All instructions same length.
The consistent placement of the source registers permits this.
Use of L1 caches to reduce contention.
Multiple reads/write.
Assume:
Instruction class times:

Clock periods for the two implementations?
Execution example:
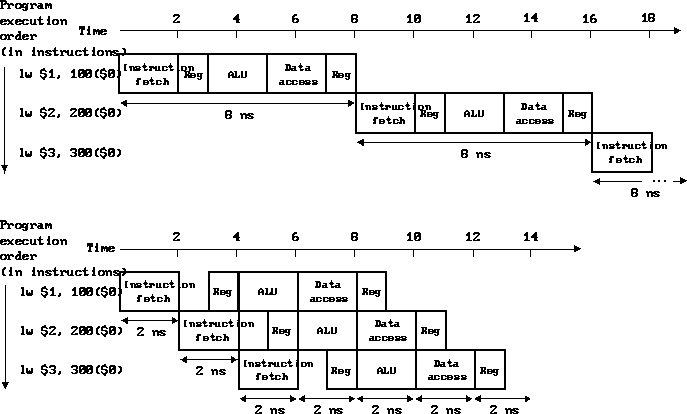
Note that pipelined register file reads are done during the second half of the clock cycle and writes are done during the first half. Why?
Consider the speedup:
Do we achieve that?
Consider the execution of 1,000 instructions and compute the actual speedup.
What happened? The cost of the pipeline registers.
Consider: