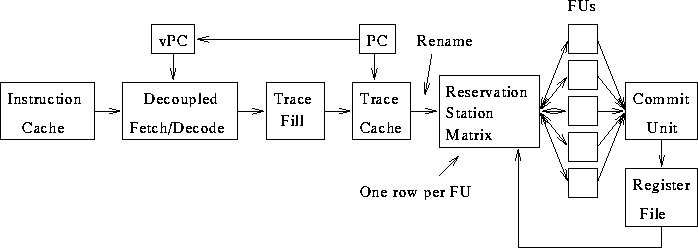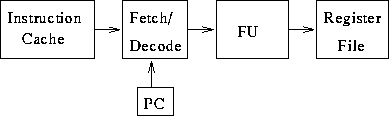
- Effects of branches on fetch rate from cache, pipeline stalls.
- Single ALU.
- ``Long'' instructions.
Tom Kelliher, CS 220
Oct. 22, 1997
Nothing new.
add r1, r2, r3 # 1 add r4, r1, r5 # 2 sub r1, r2, r3 # 3 add r6, r1, r3 # 42 depends upon 1. Does 3 really depend on 1 and 2?
load r1, 5(r2) add r3, r4, r5To maintain program semantics, instructions must commit in order.