Caches
Tom Kelliher, CS 240
Mar. 31, 2000
Read 7.3.
Memory hierarchy, terminology, cache basics.
- Direct mapped caches, DECStation 3100. Exploiting spatial locality.
- Handling cache misses.
- Memory system design.
Caches: Handling misses. Write-through, write back caches. Memory
design support for caches.
Direct mapped cache:
A cache structured such that a memory block is associated with exactly one
cache block, based upon the address of the memory block. The usual
algorithm is:
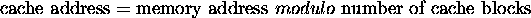
By definition, multiple memory blocks map to the same cache block:
Let's design our first cache. Parameters:
- Direct mapped --- a memory block maps to exactly one cache block.
- Block size is one word.
- Eight blocks.
- Memory size is 64 words, byte addressable (always the case).
Questions:
- How many bits for the cache?
- Consider the memory trace: 22, 26, 22, 26, 16, 4, 16, 18, run on a
cold cache. How many hits, misses? What's the hit rate? What are we
missing from the cache design (tag bits).
- Why don't we need to store the entire memory address?
- What about a valid bit?
- Now, how many bits for the cache?
DECStation 3100:
- MIPS R2K.
- 64KB cache D- and I-caches. Block size is 4B.
- 32-bit address space.
Questions:
- How is the address partitioned?
- How many bits per block?
- How many bits for the cache?
Consider:
- Design tradeoff of unified, split caches: higher hit rate (better
management of cache lines), higher cache bandwidth.
- Memory addresses come from PC or ALU.
- Read hit sequencing.
- Read miss sequencing.
Write-through, write-back caches: memory consistency (multiple bus masters)
and memory utilization reduction. Tradeoffs.
- Write hit/miss sequencing for a write-through cache.
Three cases:
- Instruction fetch miss: stall pipeline until we load the instruction
from a lower position in the hierarchy.
PC-4 business in the text.
- Data fetch miss: stall pipeline as for a lw hazard. Or, keep
going, until the data is actually needed.
- Data store miss: stall pipeline. Or use a write buffer (L3
cache), to perform writes ``later.'' Must stall if write buffer is full.
Loads must snoop the write buffer.
Let's design another cache. Parameters:
- Direct mapped.
- Block size is four words. Why would we want a larger block size?
(Exploit spatial locality)
Consider the hit rate when fetching eight words consecutively with block
sizes of one and four words.
To a point, increasing block size increases the hit rate. At what point
does this break down?
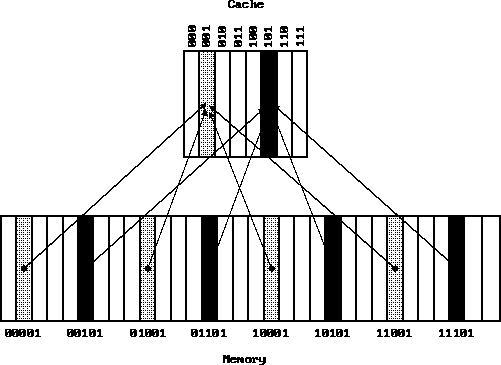
- 4K blocks.
- 32 bit memory space.
Questions:
- How many bits/block? Total size of the cache?
- Size of the data portion of the cache, in bytes? (This is the number
you see quoted.)
Organization of the cache:
Consider:
- Why would we want a larger block size? (Exploit spatial locality)
Consider the hit rate when fetching eight words consecutively with block
sizes of one and four words.
- To a point, increasing block size increases the hit rate. At what
point does this break down? Why? (Fewer blocks.)
Also, the miss penalty time will increase because of larger memory
transfers.
- How can a load instruction result in a memory write? How can a store
instruction result in a memory read?
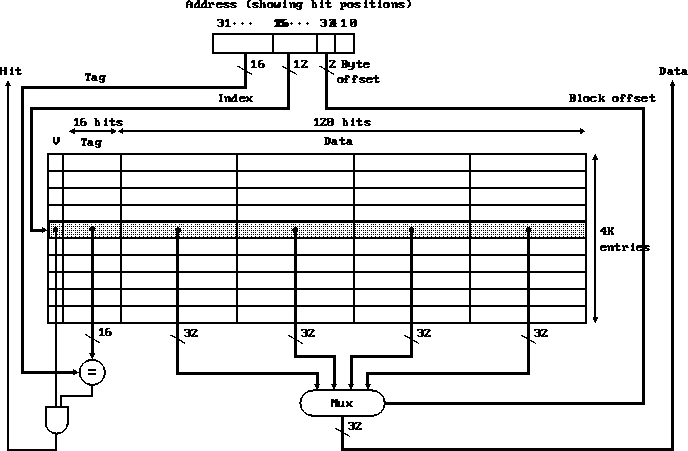
Three memory organizations:
What is interleaving and its history?
Memory access delays:
- One cycle to send an address. To access a block, we send just one
address.
- 15 cycles to allow DRAM operation to complete.
- One cycle to transmit data.
Compute the bytes/cycle for each organization for four word blocks.
Points to consider:
- The real point of interleaving is that we now have several
independent memories.
So we can perform several writes simultaneously, assuming we can write
single words. This increases our write bandwidth, leading to fewer stalls.
- But, DRAM sizes keep increasing, decreasing the number of banks for a
given memory size.
Thomas P. Kelliher
Fri Mar 31 08:48:31 EST 2000
Tom Kelliher