Code Scheduling on a Superscalar Pipeline, OOE Execution
Tom Kelliher, CS 240
Feb. 23, 2000
Collect assignment 1.
Code scheduling.
- Code scheduling examples.
- OOE: scoreboarding, Tomasulo, committing instructions.
PSU TEE.
Pentium Example: basically one integer and one
floating point unit; no instruction alignment requirements.
Suppose you don't have hardware integer multiply. Then you'll need
something like:
a = mutiplicand; /* $s1 */
b = multiplier; /* $s2 */
product = 0; /* $s3 */
bit = 1; /* $s4 */
for (i = 0; i < 32; ++i) /* $s5 */
{
if (b & bit)
prod += a;
bit += bit;
a += a;
}
Which might compile to:
top: and $t0, $s2, $s4
beq $t0, $0, skip
addu $s3, $s3, $s1 /* addu1 */
skip: addu $s1, $s1, $s1 /* addu2 */
addu $s4, $s4, $s4 /* addu3 */
addi $s5, $s5, -1
bne $s5, $0, top
We can't get any speedup here.
Suppose we assume we can perform two R-format instructions simultaneously:

Assumptions:
- Branch target must be double word-aligned.
- The instruction paired with a branch is always executed. (Text
appears to assume this. In a sense, this is the delay slot here.)
- The instruction pair slot following a branch instruction pair is not
a delay slot. (Not a good assumption.)
Let's unroll once:

Two types we'll examine:
- Scoreboarding: CDC 6600, 1964, first pipelined supercomputer,
load/store, 16 functional units: 4 fp, 5 load/store, 7 integer.
- Tomasulo's algorithm: IBM 360/91, 1967, the supercomputer that made
the Justice Department look at IBM. 360 architecture had only 4 fp
registers, long memory access, long fp delay. Tomasulo's algorithm was
designed to overcome this.
This lay, forgotten, for over 20 years...
This is really independent of scalar/superscalar execution.
- Uses only ISA registers.
- Instructions issue in order to FUs.
- Instructions execute out of order.
- The scoreboard is hardware which determines when an FU can
begin: source register values ready and complete: destination register
value no longer needed.
- Does not eliminate WAR or WAW dependencies. So, what good is it?
- Uses reservation stations (physical registers).
- Instructions issue in order to reservation stations.
- Instructions execute out of order.
Block diagram:
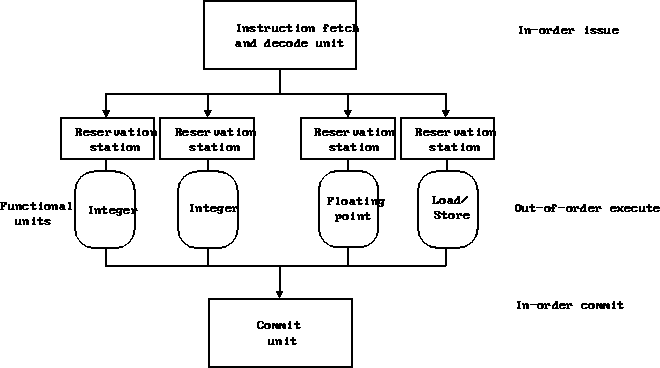
Example FUs:
- Integer.
- FP.
- Load/Store. Write buffers.
- Branch.
- Instructions must commit in order, otherwise imprecise interrupts.
- The reorder buffer: instructions placed in order there.
- An instruction cannot commit until:
- Branches resolve.
- Instructions before it commit.
- The value it produces is ready.
- Multiple commits per cycle.
Thomas P. Kelliher
Tue Feb 22 16:51:03 EST 2000
Tom Kelliher