Caches
Tom Kelliher, CS 240
Apr. 5, 2000
Homework, due 4/12.
Write-through, write-back caches.
Snooping caches.
Exploiting spatial locality.
- Multiple words/block cache.
- Memory system design.
- Measuring cache performance.
Associativity.
Let's design another cache. Parameters:
- Direct mapped.
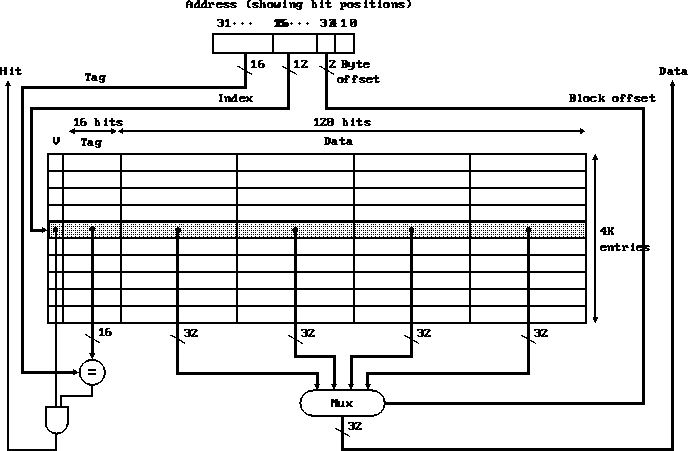
- Block size is four words. Why would we want a larger block size?
(Exploit spatial locality)
Consider the hit rate when fetching eight words consecutively with block
sizes of one and four words.
To a point, increasing block size increases the hit rate. At what point
does this break down?
- 4K blocks.
- 32 bit memory space.
Questions:
- How many bits/block? Total size of the cache?
- Size of the data portion of the cache, in bytes? (This is the number
you see quoted.)
Organization of the cache:
Consider:
- Why would we want a larger block size? (Exploit spatial locality)
Consider the hit rate when fetching eight words consecutively with block
sizes of one and four words.
- To a point, increasing block size increases the hit rate. At what
point does this break down? Why? (Fewer blocks.)
Also, the miss penalty time will increase because of larger memory
transfers.
- How can a load instruction result in a memory write? How can a store
instruction result in a memory read?
Three memory organizations:
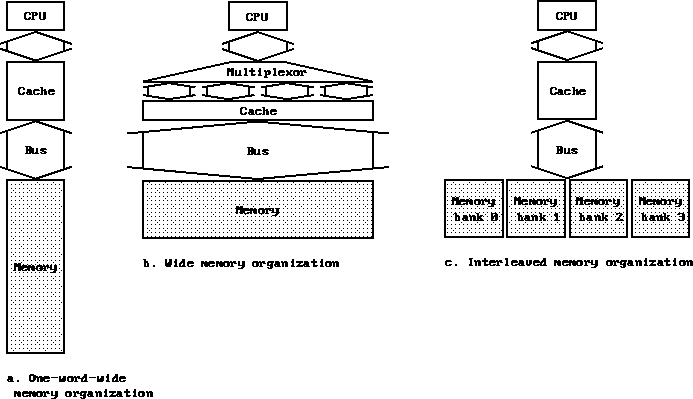
What is interleaving and its history?
Memory access delays:
- One cycle to send an address. To access a block, we send just one
address.
- 15 cycles to allow DRAM operation to complete.
- One cycle to transmit data.
Compute the bytes/cycle for each organization for four word blocks.
Points to consider:
- The real point of interleaving is that we now have several
independent memories.
So we can perform several writes simultaneously, assuming we can write
single words. This increases our write bandwidth, leading to fewer stalls.
- But, DRAM sizes keep increasing, decreasing the number of banks for a
given memory size.
Two Equations:

Consider a gcc run:
- I-cache miss rate is 2%. D-cache miss rate is 4%.
- CPI is 2, assuming no memory stalls.
- Miss penalty is 40 cycles.
- 36% of instructions are load or store.
What would be the speed-up of a machine with a perfect cache? (1.68.)
Suppose we improve the pipeline so that the CPI is now 1. Repeat. (2.36.)
Compare the speed-up of a real machine with a doubled clock rate against
the original real machine. Assume the memory system has the same cycle
time. (1.41.)
Thomas P. Kelliher
Wed Apr 5 09:50:04 EDT 2000
Tom Kelliher