Introduction to Superscalar Execution
Tom Kelliher, CS 240
Dec. 2, 2005
Collect homework.
Caches.
- Introduction to superscalar pipelining
- Data dependencies.
- Out of order execution.
- Multiple Instruction Issue
- In-order execute pipeline and instruction scheduling.
Multi-threaded processors.
- Historical Progression of IPC:
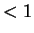 ,
, 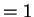 ,
, 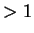 . The entire pipeline must be widened.
. The entire pipeline must be widened.
Challenges: small register files, multiple-branch predictions, multiple
line fetches from caches.
- Range of parallelism: coarse- to fine-grained.
- Superscalar techniques address ILP. Let's parallelize a
sequential binary.
- What's the upper bound on IPC? It depends.
Text processing: low, mostly.
Image processing, multimedia: high.
Median operation on an image example:
medianImage(image dest, image src)
{
for each pixel, p, in src
p in dest = medianPixel(p in src);
}
medianPixel(pixel p)
{
find the <= 8 neighboring pixels of p;
compute and return the median value;
}
Challenges: exposing potential ILP to the compiler.
Example. Parallelize the following:
sum = 0;
for (i = 0; i < last; ++i)
sum += array[i];
- Compiler techniques: loop unrolling, invariant code migration,
strength reduction, etc.
- RAR. Not a problem at all.
- RAW. A ``true'' dependency.
- WAR. A ``false'' dependency.
- WAW. Another ``false'' dependency.
Consider the code segment:
r1 = r2 + r3
r4 = r1 + r5
r1 = r6 + r7
r8 = r1 + r4
ISA registers vs. physical registers. Register renaming?
Rename the previous example where the Register Alias Table (RAT) is
initially:
r1 -> p12 r2 -> p6 r3 -> p9 r4 -> p15
r5 -> p1 r6 -> p10 r7 -> p8 r8 -> p14
Free List: p5, p11, p13, p4.
Which dependencies were removed? Which remain?
- What is it?
- In-order completion.
- How is it done?
- In-order execution case.
Structural hazard stalls.
- Out of order execution case.
Only stall if no free list entries.
- This is ``simple'' case.
Consider two-instruction issue.
Must consider:
- Structural hazards.
- Data hazards.
- Control hazards.
How to handle?
- Instruction pairs must be aligned.
- First instruction: R-format or branch.
- Second instruction: Memory access. (Add an address adder.)
- If first instruction stalls, both stall.
- Second instruction may stall due to data, control dependencies.
The pipeline:
What are the inter- and intra-instruction pair dependencies?
What are our options in increasing the functionality of that second ALU?
(reg = reg op immed instrs, reg = reg op reg instrs) Additional
dependencies?
Consider the code segment:
sum = 0;
for (i = 0; i < last; ++i)
sum += array[i];
Which might compile to:
top: lw $t0, 0($s1)
addu $s2, $s2, $t0
addi $s1, $s1, -4
bne $s1, $0, top
How will the code be scheduled?
| -- |
lw |
| addi |
-- |
| addu |
-- |
| bne |
-- |
The addi could be raised, but what's it gain?
Suppose we unroll once:
top: lw $t0, 0($s1)
addu $s2, $s2, $t0
lw $t0, -4($s1)
addu $s2, $s2, $t0
addi $s1, $s1, -8
bne $s1, $0, top
Where are the stalls? How can we introduce temp variables to eliminate
some stalls?
How will the improved code schedule?
| addi |
lw |
| -- |
lw |
| addu |
-- |
| addu |
-- |
| bne |
-- |
Is this an improvement?
By the way, what happens with the lw offsets?
Unroll twice more:
| addi |
lw |
| -- |
lw |
| addu |
lw |
| addu |
lw |
| addu |
-- |
| addu |
-- |
| bne |
-- |
Is this an improvement?
When do you stop?
Thomas P. Kelliher
2005-11-29
Tom Kelliher
![\begin{figure}\centering\includegraphics[width=6in]{Figures/f0658.eps}\end{figure}](dec02img4.png)