Performance, Microprogramming
Tom Kelliher, CS26
Oct. 23, 1996
Don't cares on truth tables.
Simplified performance of a particular program:
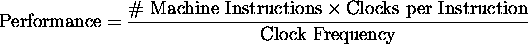
Poor performance of single-bus CPU implementation:
- Serialization of register transfers.
- Multiple clocks per instruction.
- Very little parallelism.
- Poor resource utilization.
Poor relative to what?
- One instruction per clock execution. (First achieved by RISC
architectures.)
- Multiple instruction per clock execution --- superscalar execution.
How achieved?
Multiple buses!!!
This organization allows an actual addition to be done in one clock.
How are the other sub-cycles affected?
- Simultaneous PC increment and MAR load.
- Direct, indirect, indexed, immediate addressing.
- MDR transfers.
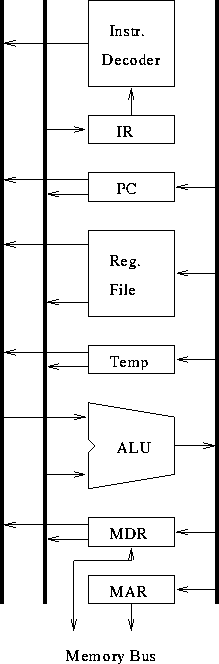
Instruction Unit.
- At beginning of each cycle, CPU stalls waiting on instruction fetch.
- Next fetch (maybe) can be overlapped with current execute.
- Buffers a few instruction --- caches small loops.
- Branch prediction.
Small, fast memory placed between CPU and main memory.
Discussed in detail later.
- Superscalar (more execution units).
- Why two L1 caches?
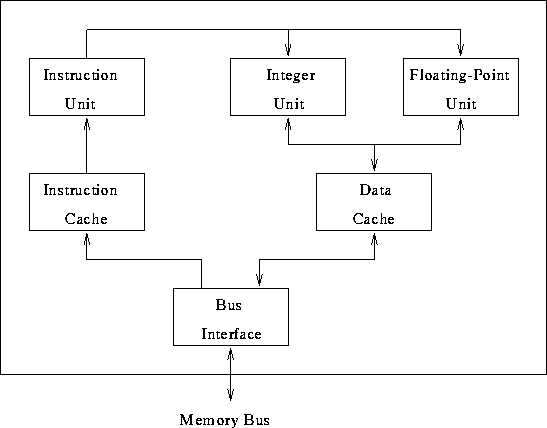
Consider a typical 3-stage RISC instruction cycle:
Consider pipelining it.
First the what, then the why.
- Data path (defn):
- Register file.
- ALU.
- MDR, other ``data'' registers.
- Control unit (defn):
- IR, PC, MAR.
- Instruction decoder/encoder.
- Data path needs sequences of 0's and 1's on control inputs to execute
instructions.
- Control unit provides the sequence.
- Can the control unit be replaced with a memory (control store) whose
output is connected to the data path's control inputs?
- Contents of the control store --- a program for each instruction.
Microprogram. Microinstructions.
- How do we sequence the control store? Required operations:
- Straight line execution.
- Unconditional branches.
- Conditional branches.
A microsequencer:
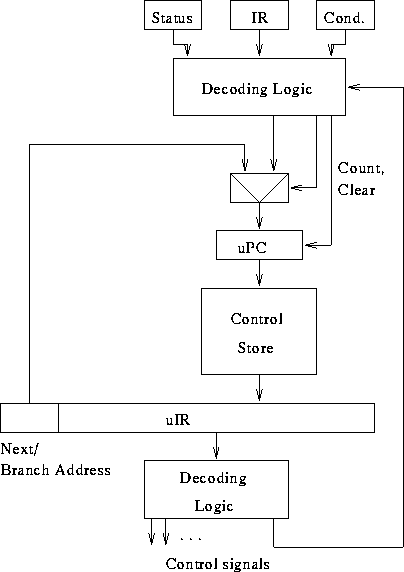
- Horizontal microcode.
- Vertical microcode.
- Limiting the size of the control store:
- Commonalities between microroutines.
- Utilize branching to ``factor out'' common code.
- Micro-subroutines!!!
- Prefetching microinstructions?!?
Advantages off the bat:
- Easier debugging.
- Quicker to market.
- Emulation.
- Extending the instruction set.
- Easier upgrades.
Disadvantages off the bat:
- Slower than hard-wired.
1970s technology:
- Main memory was core; control stores were solid state (10 times
faster).
- No caches.
- 8Kb ROM = 8 bit register, space-wise.
Implications:
- Program speed was proportional to program size (bandwidth).
- Control stores were ``cheap.''
Solution: Microprogramming and richer instruction sets
- Simplify compiler construction.
- Close the ``semantic gap.''
- Improve architectural quality be decreasing program size and
bandwidth.
- Microinstructions were ``faster'' than regular instructions.
- Register-based architectures were unwieldy; use stack-based or
memory-memory.
1980s technology:
- Main memory was now solid state.
- Caches were common.
- CMOS VLSI.
- Control store ROMs were becoming RAMs (bugs).
- Compilers were sub-setting architectures.
Some weird developments:
- Writable control stores.
- Virtual memory at the control store level.
- Nanocode.
Two CPUs:

RISC design philosophy:
- Functions should be kept simple unless there is very good reason to
do otherwise.
- Microinstructions should not be faster than simple instructions.
- Microcode is not magic.
- Simple decoding and pipelined execution are more important than
program size.
RISC CPU traits:
- Load/store; operations are register-register.
- The operations and addressing modes are reduced.
- Instruction formats are simple and do not cross word boundaries.
- RISC branches avoid pipeline penalties.
Thomas P. Kelliher
Wed Oct 23 22:49:36 EDT 1996
Tom Kelliher